If Google ran the arXiv: prospects of data mining in academia
This is the last, and most ambitious, of a three-part series on Web 2.0 and the arXiv. Part I (Digg), Part II (Amazon).

Can artificial intelligence improve the way we do science?
A brief recap. In Part I we discussed the idea of incorporating comments on the arXiv. The proposal required active participation from many users. In Part II we suggested an improvement based on personalised recommendations based on passive user data. This, however, still depended critically on user activity.
What would the arXiv be like if Google–masters of data mining–were at the helm?
How Google works
I have only a heuristic understanding of how Google works, but the search engine’s goal is clear: `understand’ the world’s data so that it can perfect the art of information searches. The technical details aren’t too important, but my cartoon picture (literally) is this:

Google’s artificial intelligence (AI) is represented by the comic book character, Brainiac. It consists of fancy algorithms to process information: it cross-correlates data, mimicking `understanding.’ In order to do this, however, it needs a large body of data for robust correlations, represented by the arXiv and a useful textbook. All this comes together at the search engine, the interface for making queries of the AI’s `understanding’ of the world.
For Google’s web search, the output is a list of relevant websites. But the real power of the AI is the database of correlations itself. For example, I recently had the pleasure of speaking with a fellow Marshall scholar regarding work he’s done on essay grading based on similar algorithms [1]. My basic comprehension is that the AI can `understand’ written ideas by extending works of finite length to include text that the work would have included if it were of infinite length. (Or at least length on the order of the size of the corpus of data.)
Read that sentence again if it was unclear, it’s the most important sentence in this post. It’s almost a poetic idea. Instead of asking the AI to compare abstract ideas described by finite words, it extends the words to include all possible words to describe the abstract idea. Extended this way, abstract ideas can be processed by a computer. Two parenthetical footnotes are in order [2], [3].
The paradigm for this sort of AI:
You have all this data and taught the Internet to store it. Now you need to teach the Internet to read it and use it.
Scaffolding for SPIRES
So how might this be applied to the repository for all scientific knowledge? Google’s web crawlers already scan the arXiv’s pdf document, what more is there to do?
Think about SPIRES. While the arXiv is a database for e-prints, SPIRES is, in essence, a database for arXiv metadata. It stores information about authors, institutions, citations, tags [4], and other data that can be just as useful to researchers. Here’s a cartoon of the analogy:

If Google were in charge of our primary electronic repository of HEP knowledge, the revolution wouldn’t be in the arXiv, but rather in SPIRES. `Googlesque’ AI holds tremendous potential for automatic parsing and dynamic generation of metadata.
Consider the arXiv identifiers. The current system has a set of subject divisions that are both coarse and vague. A paper on supersymmetry might be somewhere in-between “hep-ph” and “hep-th.” But even this classification is too broad to be of much use to people scanning the day’s e-prints. Researchers want to know more details: hep-ph/th > supersymmetry > breaking > dynamic SUSY breaking > collider signatures.
It is hopelessly impractical to have folks behind SPIRES rewrite subject divisions over and over again. But a sufficiently intelligent system could do this automatically, identifying new research directions (and sub-directions) and merging obsolete ones. Of course, users and authors would be able to vote to override automatic tags. And further the AI would incorporate such overrides as part of its seed data.
What if we take this a step further? If we can tag it, we can map it. We could use these dynamically maintained tags to map out our knowledge of high energy physics, paper-by-paper. Imagine something like this, only much larger and plotted on a large multidimensional space. Even though we humans wouldn’t be able to navigate such a representation, the AI would be right at home.
A map of High Energy Physics
What I mean by a `map of our knowledge of HEP’ is an abstract structure is made up of ideas, represented to AI as explained above. The nodes this structure would be made up of academic papers, with a skeleton formed out of the papers’ inter-relationships. ‘Hard’ links are formed between a paper and those that it cites. Further, ‘soft’ links based correlations extracted by the AI. [5] The end result would be an objective, automated, quantifiable version of the following cartoon map of new physics by Professor Murayama:

Image from Prof. Murayama’s Lepton Photon ’03 talk.
Such a system would identify and categorize new trends. It would be fascinating to see the extra dimenion ‘branch’ of hep-ph/th papers grow on such a map since 1998. I imagine the process would be very similar to actual plant stems that grow towards untapped resources like sunlight. Further, this sort of map would create a boundary between what is ‘known’ and ‘unknown’ in our field. [See above image.] It would be a graphical representation of what has been done and what is yet to be done for new directions.
For example, given a new model X such a map could be used to produce a checklist of `things to be done,’ including:
- Can X solve the hierarchy problem?
- Has it been supersymmetrized?
- Does it predict a dark matter candidate?
- What are the cosmological implications?
- How is it constrained by CP and flavour?
- What is the LHC/ILC spectrum?
- …
These are all things physicists think about automatically when presented with new ideas. Why? Because these have been applied to every other model A, B, C, … . A Googlesque AI would be able to identify these patterns from the corpus of past papers and map them as the boundary of what is known and unknown for a given research branch [6].
A bit more sci-fi
If we wanted to dream a bit more, one could imagine a Googlesque AI working with metadata about authors. It could track researchers’ current interests and identify potentially fruitful collaborations between researchers with confluent interests. Further, it could suggest conferences to researchers based on the proportion of attendees with whom collaboration is likely to be fruitful.
A very clever AI could even summarise research directions, aggregating related papers and `explaining’ their relations to one another.
If you wanted to get even more sci-fi, you could start thinking about what an intelligent AI could do if you taught it to parse 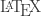
A bit more down-to-earth
If one is more interested in what a good AI can do for us closer in the future, here are three thoughts.
First of all, an system with [reliable] detailed automated tags would make it really easy to keep up with papers in specific fields. Instead of subscribing to an RSS feed for hep-ph, one could specifically keep up with hep-ph/th > supersymmetry > breaking > dynamic SUSY breaking > collider signatures. You’ll never have a paper slip your attention just because it wasn’t cross-listed with the right identifier.
Secondly, a map as described above would have great value to historians. It would help determine which papers really seeded new research directions and how different researchers contributed to these directions — something that can be hidden in simple citation analysis.
Finally, the AI would be able to connect papers `horizontally,’ i.e. relate similar papers that are published at the same time and hence don’t necessarily cite one another. The AI would be able to identify that the papers were sourced from the same idea, even if they don’t explicitly cite the same sources. This would be a huge benefit for literature reviews. In fact, SPIRES’ bibliographic tools could be extended to `complete’ a list of references to include suggestions of other papers that an author might have missed. [7]
Killer app: grad education
There’s one last point that I wanted to emphasize with respect to AI and data mining in academia, but I think it’s the most important point: improving the way we educate research students.
It’s easy to look back and envy previous generations of physicists. With our 20/20 hindsight, it seems like everything was ripe for them to make great leaps forward. It’s not hard to imagine that every physics generation has felt this way, but there is a real problem.
At the end of the day the corpus of `prerequisite’ knowledge is increasing more quickly that we are able to effectively condense it pedagogically. Even though most university curriculae have cut out topics such as fluid mechanics to make room for general relativity and quantum field theory, students still have to wait longer and longer before they can reach the cutting edge of research. [8] Granted, there’s some wiggle room in efficient teaching of mathematics and science to younger students, but I suspect that within my lifetime it will be an issue to even get up to the forefront.
The problem is that pedagogy improves on the timescale of generations: consider, for example, how the last three generations of quantum field theorists have each had different `canonical textbooks’: Bjorken & Drell, Peskin & Schroeder, Srednicki (or whatever your current favourite is). From this perspective, the bottleneck is having a senior researcher pedagogically condense the new ideas and perspectives of his or her career into a new text for the next generation.
There is some further support in the form of review articles: papers that are written as an introduction to recent research developments; though these are often very specific in scope compared to subject-reviewing textbooks.
A `Googlesque’ AI incorporated into SPIRES could improve this by aggregating pedagogical material automatically. Its current attempt at this is human-generated and is pathetically outdated, especially compared to student-generated wikis compilations. But a well-trained system could not only tag important review articles, but it could organise them based on topic and popularity.
More importantly, with some user-generated data, one could imagine a system where the system keeps track of not only which reviews are useful, but which students find the reviews useful. [9] Hence instead of just suggesting review articles based on what’s popular, the system would suggest reviews based on why they’re popular: a student with a background formal theory and mathematics may find the Argyres SUSY review useful, while a student with a more phenomenological background might find the Martin review more accessible.
Where could we go with this? A graduate student spends a lot of time keeping up with papers on the arXiv. If one allows the AI to keep track of this activity, it can keep up with a student’s progress and even guide the student based on research interests and what similar students have found useful. Instead of waiting for a generation for a textbook with a modern treatment of a subject, the system could actively assess and promote `modern’ review articles as they are written.
If you’ll allow me to be even more sci-fi, such a system could even parse a review article’s tex file and determine conceptual dependencies based on the references within the work. It could then actively mix and match pieces of different review article to write customised introductory `books’ on a given subject.
Imagine you’re a graduate student learning supersymmetry. This system would then combine pieces of different review articles (and open-access books) into a presentation specifically tailored to you based on your individual background. You wouldn’t have to worry about searching for different papers to fill in gaps in your knowledge — the AI would fill them in for you. In true Web 2.0 fashion, the resulting customised presentation would be a wiki, so that the student can digitally `write notes in the margin.’
Limitations
I’ve allowed myself to be optimistically futuristic here. Further, aside from heuristic descriptions, I’ve avoided any details about the the feasibility of adapting AI technology to these issues. This is partially to hide the limits of my own understanding; for all I know none of this is feasible (or maybe some engineer in Google has already done it). But the main point of this post was to think big, even if comes at the cost of realism.
The most important caveat, however, is that nothing stated above actually replaces the research process and especially the inherent creativity required for progress. In some sense, the goal of all of this is to allow researchers to focus more on the creative process at the heart of research instead of the auxilliary tasks (e.g. checking the arXiv) associated with it.
Footnotes
[1] My rudimentary knowledge of ‘how Google works’ comes from conversations with my colleague, Mark, a multi-talented spoken word poet, computer scientist, and humanist. Unfortunately, I’m a dense physicist, so any inaccuracies are certainly my own.
[2] Have you ever wondered why Google is bothering to try to digitize all printed text, even though copyright prevents them from making most of it available to the web? Google’s not [just] digitizing text out of altruism for mankind. By doing this their corpus of human knowledge is extended to include practically everything ever written in English. As I vaguely argued above, an AI (e.g. neural net) is only as good as the size of its seed data.
[3] For a fictional description of AI, see R. Powers’ Galatea 2.2. The book is certainly not the author’s best (see this or this instead), but at least the first half is insightful to a lay reader interested in these things.
[4] One thing that I’ve omitted from my discussions of Web 2.0 science are tags and sites such as del.icio.us. They go a long way to organize the web, but it is my belief that Google has largely leap-frogged this technology.
[5] The distinction between `hard’ and `soft’ links is important. Hard links are part of the AI’s seed data, while soft links are extracted by the AI. Thus the problem of applying this sort of AI to academia is considerably simpler than the more general case of teaching a computer to read and understand novels (see footnote [3]), which have no a priori structure of connections to one another. The presence of a pre-existing, causal (new papers cite old papers) network of relations that the AI can build upon makes it easier for the AI to interpret relationships between academic works the way a human would.
[6] I should quantify that when I define the boundary between ‘known’ and ‘unknown,’ I really mean the boundary between ‘known knowns’ and ‘known unknowns.’ It’s arguable whether or not a sufficiently intellgient AI could point the way to ‘unknown unknowns.’
[7] By the way, anybody who hasn’t heard of SPIRES’ Bibliography Services should go check it out right now. I can’t imagine an easier way to write an error-free bibliography.
[8] Consider, for example, that Feynman taught himself quantum mechanics as an undergraduate and was then already at the forefront of research. Today quantum mechanics is a standard course taught to second year undergraduates and even graduate courses in quantum field theory won’t necessarily take you to the frontier of current research. Conversely, it’s fascinating to look at very old physics textbooks (the Cambridge libraries have plenty) to see the chapters devoted to archaic ideas like the aether.
[9] This is more like the Amazon technology I described in Part II of this series.
Filed under: Science 2.0 | 5 Comments
Flip Tomato

I'm a postgraduate, expatriate physics student. RSS Feed.

-


What if the AI becomes sentient, starts publishing papers, and puts us all out of jobs?
Jon — you’re assuming that budget cuts to each of our respective national science funding organizations don’t put us all out of jobs beforehand. 😦
Go to http://labs.google.com/sets
enter lepton in the first box,
enter photon in the second box,
and press “large set”.
Try new version of http://xstructure.inr.ac.ru/-a service for browsing and searching papers in arxiv.org